Heart Disease Prediction Using Logistic Regression vs Random Forest
In this blog post, I analyze the UCI Heart Disease dataset to predict whether a patient has heart disease using two machine learning models: Logistic Regression and Random Forest. This project builds on my Titanic dataset analysis but introduces more features, non-linear relationships, and advanced evaluation methods like AUC and ROC curves.
The dataset includes medical features like age, cholesterol, chest pain type, and max heart rate. The target column is binary: 1 means the patient has heart disease, 0 means they don’t.
First, I performed preprocessing by checking data types, confirming there were no missing values, and selecting the most important features based on a correlation heatmap. I chose: age, sex, chest_pain_type, Max_heart_rate, oldpeak, and exercise_induced_angina. I used one-hot encoding via pd.get_dummies() to convert categorical columns into numeric format.
I trained two models for comparison.
Logistic Regression Results:
Accuracy: 0.80
This model performed reasonably well and gave a solid baseline. It’s interpretable and works well for simple, linear relationships, but slightly underfit the data.
Random Forest Results (after tuning):
Train Accuracy: 0.88
Test Accuracy: 0.82
Initially, the Random Forest model gave 100% accuracy, indicating overfitting. I addressed this by tuning key hyperparameters: max_depth=5, min_samples_split=10, and min_samples_leaf=5. After tuning, the model showed excellent generalization.
To evaluate performance, I plotted an ROC curve. The Area Under the Curve (AUC) was 0.92, indicating excellent predictive ability. Here’s the ROC plot:
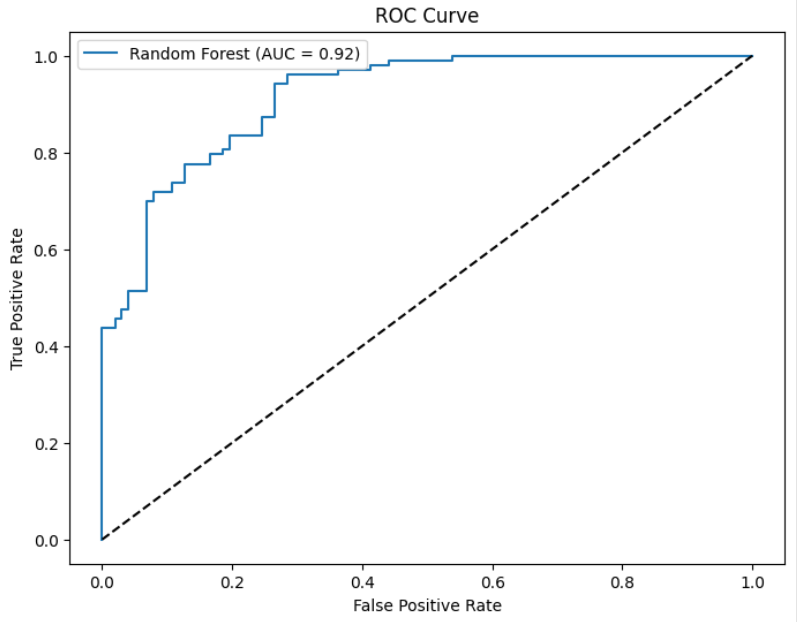
Key Insights:
- Max_heart_rate and oldpeak were the strongest indicators of heart disease.
- Logistic Regression was a good start but limited by its linear nature.
- Random Forest, with proper tuning, captured more complexity and performed better overall.
You can view the full Colab notebook here.
This project was a significant step up from the Titanic dataset in terms of modeling complexity and medical relevance. Next, I plan to explore XGBoost, text classification, or unsupervised learning!